In Part 1 we discussed what a data mesh is, its foundational principles, and how it solves current data management challenges. Data mesh enables analytics at scale; it allows greater flexibility and autonomy for data owners enabling easier data experimentation and innovation while reducing the burden on data teams.
Implementing data mesh in an organization is a journey and not a one-time project. As data continues to grow, data mesh allows organizations to increase agility and scalability and provide faster time to value by making your data discoverable, accessible, and secure across domains. This blog highlights the high-level process steps and technology enablers that require an organization to build a sustainable data mesh platform and covers the data mesh architecture – which include the federated governance platform, self-service data platform, and three planes (utility, data, and mesh experience).
Organizations’ business goals, strategy, and culture drive the right mix of centralization and decentralization programs. In a similar vein, organizations need to choose the right balance between centralized control and local domain autonomy that works best for them. There is no one-size-fits all approach therefore data mesh is not a panacea for all data management and data integration challenges. Organizations need to design a self-service IT architecture that can support distributed domains and data products with federated governance. Ideally, the middle ground effectively balances the needs of standardization and creativity. Organizations need to consider the following high-level generic process steps for data mesh implementation to improve time-to-market, scalability, and business domain agility. The examples below relate to a hypothetical financial services company.
1. Conduct a feasibility study: Assess the landscape (e.g., organizational culture, strategic goals, current technology stack and future tech strategy/vision).
2. Develop a business case: Identify and get approval for a business case that can be enabled with data.
3. Prepare the foundation: Set up the essential building blocks – the enabling team (for change management, communities of practice, and best practices), governance team (for federated governance) and infrastructure platform team (for building self-service platform). Change management is a critical success factor for data mesh implementation. The enabling team should ensure that organizations focus on the organizational and non-technical aspects like organizational changes, roles and responsibilities, accountability, buy-in from key stakeholders, and shifting the mindset to product thinking, etc.
4. Implement a minimal viable product (MVP).
a. Choose a business goal with identified KPIs (e.g., reduction in credit risk by 2%, reduction in loan defaults by 5%).
b. Define consumers, domains, and decentralized data products.
i. Data product is an autonomous, standardized data unit containing at least one data set to satisfy user needs. The figure below shows two domains – consumer banking and asset management. Consumer banking domain has two data products – consumer credit card profile and consumer demographics. Asset management domain has one data product – consumer asset profile.

Data Mesh is an ecosystem of data products, which should be self-described, discoverable, addressable, and interoperable. Data products include efficient processes for handling their own infrastructure, code, and data (including its metadata). Data product features include acceptable quality, availability, security, freshness, and consumer focus.
As you can see, each of the data products has input and output ports – protocols used to ingest from source and expose to consumers, discovery port to be discoverable by other consumers, metadata on itself including the operational metrics, the consumer and use cases, along with a configuration port used to configure during runtime.
c. Define personas in the system to operationalize data mesh (e.g., domain owner/consumer/engineer)
d. Configure a data catalog (environment, security, annotations, roles, etc.)
e. Develop data product (note: led by the individual domain leaders with the help of domain engineers with full autonomy on the technology stack to be used).
i. Collect and analyze consumer needs
ii. Define functional and non-functional requirements
iii. Design data product architecture
iv. Implement data product
v. Measure data product success
f. Collect feedback about infrastructure platform and analyze common needs
g. Define federated computational governance
With federated computational data governance model, the enterprise-scale data policies (integrity, usage, security, compliance, quality, encryption, etc.) are translated into algorithms and enforced automatically where feasible. The policies are decided at the central level; however, data product owners have flexibility and independence of their implementation. If needed, policy enforcement can be enabled in the self-service platform. Federated computational governance may include data product owners, platform team, security leaders, and CDO or CIO representatives to ensure all foundational elements are adhered to (e.g., CCPA, HIPAA, PCI DSS, GDPR).
h. Develop centralized self-service infrastructure platform to provision and deploy distributed platform components including automated DataOps which is an organization-wide data management practice that improves communication, integration, and automation of data flows.
The central self-serve infrastructure platform abstracts the specialized skills needed for repeatable and generic activities, thereby minimizing duplicate efforts across the data mesh by allowing teams to focus on domain-specific development and consumption. It is a “platform thinking” approach in a data context. Salient capabilities include catalog, observability, monitoring, auditing, federated identity management, storage, query engines, usability, scalability, access management, automation, etc.
i. Develop a data product marketplace for consumers. Refer to Mesh experience plane depicted below.
j. Onboard first domain to catalog, first ad-hoc data in domain-centric landscape, and first data product.
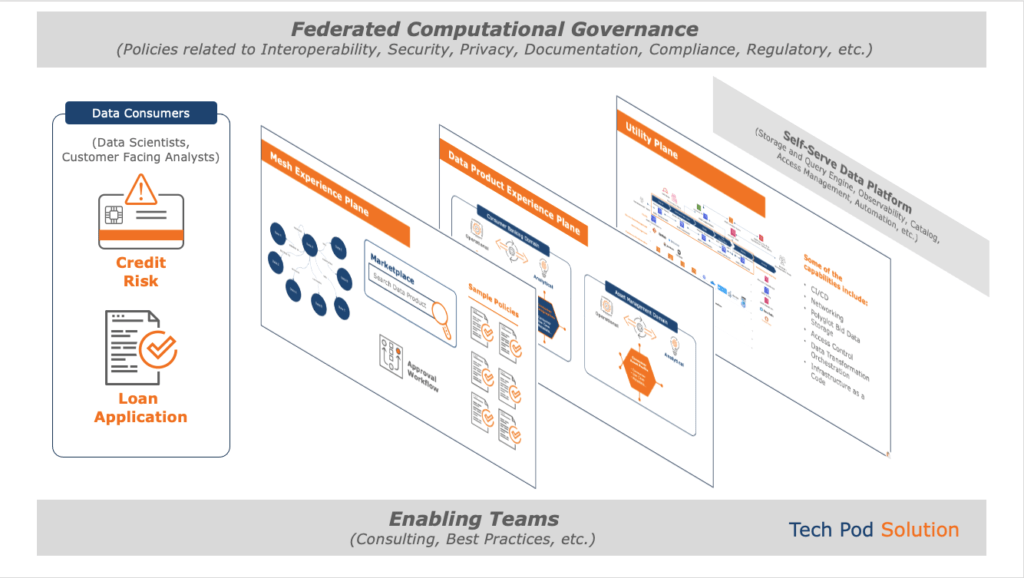
The figure above depicts the data mesh architecture through a data lens. As shown, the data platform is comprised of three planes – the mesh experience plane for new platform interfaces and capabilities, the data experience plane for all the domain-driven data product development cycle management, and the utility plane for infrastructure as a code automation.
5. Improvise based on feedback as additional data products are built and driven by agreed-upon business use cases to realize business value.
As mentioned earlier, technology is the key enabler for data mesh implementation. Depending on the organization’s technology roadmap, a variety of tools could be used. Some of the technology enablers are highlighted below.
- AWS S3 for object storage, AWS Glue for extraction, transformation, and loading (ETL), AWS Glue Data Catalog for an integrated schema-catalog, AWS Lake Formation as a rights management solution enabling data lakes across AWS account boundaries, AWS Kinesis data streams for streaming data, AWS Athena for the query engine with SQL interface, Amazon Sage Maker for AI/ML solutions, and Amazon QuickSight for visualizations. JPMC is a case in point..
- Snowflake tables for object storage, Snowflake Datawarehouse as the query engine, Secure views for data sets, Kafka for streaming data, dbt for transformation, dbt models and tests for data product definition and testing, Snowsight dashboards and a variety of data discovery and visualization tools (e.g., Sisense). DPG Media is a case in point.
- Databricks Delta Lake for object storage merges the functionality native to data warehouses and data lakes, Apache Spark for executing analytical workloads, Databricks Notebooks to write Python or Scala-based Spark code that could be scheduled for batch or streaming jobs, Databricks Notebook for MLFlow (for machine learning) and Databricks SQL for query. Zalando is a case in point.
In the next blog, we will dive into the critical success factors, topical business use cases, and lessons learned for a sustainable data mesh solution.
Infinitive has not only implemented several data mesh technology enablers using AWS, Snowflake, and Databricks but also guided organizations to blend emerging technologies with their business strategies to design, develop, and execute leading edge platforms, organizational development models, and management of complex, high performance teams. We have the know-how to help your organization “get the value out of your data.” For more information on how to implement any of these data management tools and/or approaches in your business, contact us today.